前言
现场测试遇到了一个问题,设备下挂摄像头时,视频卡顿。通过设备下挂pc,然后iperf测试发现tcp相比udp性能要低,从而他们认为是设备TCP性能较低。测试人员回来后反馈问题,让解决下设备tcp性能问题。认为视频卡顿不一定是性能问题,例如mtu什么的都可能影响到视频质量。而且公司没有验证条件(现场是apn网络),也没有更多的信息提供,认为不能一股脑的就去解决tcp性能问题,如果解决tcp性能并没有解决视频卡顿的问题岂不是尴尬。借此机会先把优化性能的几个入手处做个整理。
入手点
mtu
- MTU不匹配:如果两个通信的设备或网络链路的MTU不匹配,可能会导致性能下降。
- 分片的问题:如果某个设备或链路无法处理大于其MTU的数据包,将导致分片,这可能会导致性能下降。尽量避免分片,因为它会增加处理开销。检查设备能否处理大MTU。之前有一次的性能问题就是客户环境中有一个设备无法处理大的包,导致性能下降。 像我们的业务中有vxlan,由于数据的封装,就会导致通过它的性能要比设备带宽低。
测试设备网络带宽
确保问题不是由于网络连接本身的带宽限制或高延迟引起的。可以使用工具如iperf来测试网络性能。例如,在这次的现网测试中,先测试下两个设备的wan口带宽,再测试下通过vxlan之后的性能数据,与wan口的测试数据对比。以下,均以iperf打tcp流作测试的结果。
借用工具分析cpu、内存等
- top:大致看下设备cpu、内存利用情况。当应用或者iperf测试时看是否是两者有异常
- htop:由于在openwrt系统中,top工具比较简单,看不到详细信息,htop可以看到每个cpu的利用率
- atop:atop比htop信息更详细:各个cpu中断时间比、空闲时间比、上下文切换、中断发生次数等等。(有的top也可以看到各个cpu情况,但是我们所用的系统内装的top不支持)
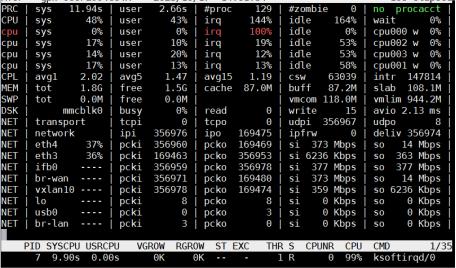 如上图所示为atop的一个结果,发现四个cpu,其中cpu0的软中断占到了100%,通过观察业务环境中的各个设备cpu情况,发现是接收端的设备上有问题。
如上图所示为atop的一个结果,发现四个cpu,其中cpu0的软中断占到了100%,通过观察业务环境中的各个设备cpu情况,发现是接收端的设备上有问题。
处理cpu软中断的着手方向
可以通过ethtool工具查看网卡的详细信息
ethtool -S eth4
NIC statistics:
interrupts [CPU 0]: 4198325
interrupts [CPU 1]: 126032
interrupts [CPU 2]: 21231
interrupts [CPU 3]: 21
interrupts [TOTAL]: 4345609
rx packets [CPU 0]: 38669955
rx packets [CPU 1]: 4648918
rx packets [CPU 2]: 733615
rx packets [CPU 3]: 18
rx packets [TOTAL]: 44052506
tx packets [CPU 0]: 14450022
tx packets [CPU 1]: 2850552
tx packets [CPU 2]: 1552784
tx packets [CPU 3]: 693131
tx packets [TOTAL]: 19546489
tx recycled [CPU 0]: 0
tx recycled [CPU 1]: 0
tx recycled [CPU 2]: 0
tx recycled [CPU 3]: 0
tx recycled [TOTAL]: 0
tx confirm [CPU 0]: 19367796
tx confirm [CPU 1]: 152865
tx confirm [CPU 2]: 25825
tx confirm [CPU 3]: 3
tx confirm [TOTAL]: 19546489
能看到各个cpu的中断次数、接收、发送的的数据包数量等
修改cpu亲和性
命令cat /proc/interrupts查看当前应用程序或者网卡对应的中断号,然后进到/proc/irq目录下看到一堆以数字命名的目录,这些数字对应cat /proc/interrupts的终端号,进入对应的目录,其中文件smp_affinity就是linux操作系统用于控制中断处理程序与 CPU 核心的亲和性。其中数字是十六进制,表示CPU核心掩码,例如,1表示中断处理程序绑定在第一个cpu上,f表示中断处理程序与四个不同的 CPU 核心相关联。
smp_affinity 中使用十六进制数字 f 通常是为了允许中断处理程序在多个核心之间均衡分配,以便更好地利用多核处理器的性能。这种设置适用于高负载环境,可以提高系统的响应速度。
使用工具:irqbalance
openwrt系统可以安装工具irqbalance,是一个用于 Linux 系统的工具,旨在优化中断请求 (IRQ) 处理,以提高系统性能。它可以自动分配 IRQ 到多核 CPU 上,以减少 CPU 内核之间的中断竞争,从而减轻系统负载,改善响应时间。
packet_steering
openwrt中有一个配置参数packet_steering,openwrt官方wiki说明特别简单,仅仅是:”Use every CPU to handle packet traffic”。同时还有一个文件:/etc/hotplug.d/net/20-smp-packet-steering。根据脚本,可以简单理解为:当 “数据包引导” 开关打开时,开启所有接口的 RPS(Receive Packet Steering) 和 XPS(Transmit Packet Steering) 功能,并且配置为所有 CPU 内核可被使用。
在我所用的设备上,就是把所有 /sys/class/net/接口名/queues/RX队列名/rps_cpus 和 /sys/class/net/接口名/queues/TX队列名/xps_cpus 默认的 “0” (关闭),改为 “f”(可以使用 CPU 核心 0 1 2 3)。
所以根据情况可以打开该开关,或许对于提高性能有好处。
RPS单纯地以软件方式实现接收的报文在cpu之间平均分配,即利用报文的hash值找到匹配的cpu,然后将报文送至该cpu对应的backlog队列中进行下一步的处理。适合于单队列网卡或者虚拟网卡,把该网卡上的数据流让多个cpu处理,在中断处理程序中根据CPU_MAP决定将报文放入哪个CPU队列中,然后触发NAPI软中断。RPS要求内核打开SMP。
其他
在各种尝试的过程中有了解过一些其他的内核参数配置项:
- tcp滑动窗口
- 接收窗口: sysctl -w net.ipv4.tcp_rmem=”1024000 8738000 16777216” , 对应文件:/proc/sys/net/ipv4/tcp_rmem
- 发送窗口: sysctl -w net.ipv4.tcp_wmem=”1024000 8738000 16777216” , 对应文件:/proc/sys/net/ipv4/tcp_wmem
- 桥的类型:由于我们设备默认桥用的是openvswitch,可以修改成内核桥,看性能是否会有改善;
/proc/sys/net/core/rps_sock_flow_entries:- 这个参数用于控制套接字流表的大小,用于跟踪传入网络数据包的信息以便将其分发到不同的处理器核心。
- 适当调整这个参数可以优化系统的网络性能,特别是在多核系统中,通过并行处理网络流量来提高吞吐量。
- 增加这个值会增加套接字流表的大小,允许更多的套接字条目,提高并行处理能力。
net.core.busy_poll: 控制在设备队列上等待套接字轮询和选择数据包的微秒数。- 当设置为非零值时,套接字将以指定的时间间隔主动检查是否有新的数据包到达,而不会进入传统的阻塞或休眠状态。这可以降低数据包处理的延迟,但会增加 CPU 负载。
net.core.busy_read: 通常用于调整与TCP套接字的读取操作(接收数据包)相关的忙碌轮询行为。- net.core.busy_poll 用于控制套接字的全局忙碌轮询行为,而 net.core.busy_read 更专注于套接字的读取操作。
/proc/net/softnet_stat:显示 Linux 内核中软中断(soft interrupt)统计信息的文件。/proc/sys/net/core/netdev_max_backlog: 控制网络设备的接收队列中允许排队的数据包的最大数量。如果队列中的数据包数量超过了这个值,新的数据包将被丢弃或拒绝,以减轻系统的负载并防止过多的数据包排队等待处理。
业余研究,如结论有误,还请各位大神赐教。该文章会在学习过程中持续更新中…