前言
开发都是调用现成的函数,久而久之我们就忘了最原始的东西,整理、回顾基础。
协议初识
协议以及模型
在TCP/IP协议套件中,常见的模型:
- OSI七层模型, 应用层、 表示层、 会话层、 传输层、网络层、数据链链路层、物理层
- TCP/IP四层模型, 应用层、传输层、网络层、数据链链路层
- TCP/IP 五层模型, 应用层、传输层、网络层和链路层、物理层。
各个层次包括四个主要的层次:应用层、传输层、网络层和链路层。 其中应用层属于应用程序,传输层、网络层、数据链路层属于内核程序。
物理层是传输的光电信号,数据链路层传输数字信号,网卡就是将光电信号转换成数字信号,数字信号转换成光电信号,不属于上面任一一层。
每个层次都有特定的协议和功能。以下是这些层次中的一些常见协议:
应用层:
- HTTP(超文本传输协议):用于Web页面的传输。
- FTP(文件传输协议):用于文件传输。
- SMTP(简单邮件传输协议):用于电子邮件传输。
- POP3(邮局协议版本3):用于接收电子邮件。
- IMAP(Internet消息访问协议):用于远程管理电子邮件。
传输层:
- TCP(传输控制协议):提供可靠的、面向连接的数据传输。
-
UDP(用户数据报协议):提供无连接的、不可靠的数据传输。 网络层:
- IP(Internet协议):负责数据包的路由和寻址。
- ICMP(Internet控制消息协议):用于网络诊断和错误报告。
- ARP(地址解析协议):用于将IP地址映射到物理MAC地址。
- OSPF(开放最短路径优先协议):一种路由协议,用于在网络中找到最短路径。
链路层:
- Ethernet:用于局域网中的数据链路层通信。
- PPP(点对点协议):用于串行连接的数据链路层通信。
- IEEE 802.11(Wi-Fi):用于无线局域网的数据链路层通信。
协议栈是什么?
顾名思义,协议栈即一系列协议组成的协议族。 那为什么协议簇?
栈:是一种数据结构,先进后出。当双方通信时,先加的协议头后处理,后加的协议头先处理,TCP/IP报文封装、解封装就是这样的。
TCP/IP封包流程
以HTTP报文为例:
||==========|| +------------+
|| HTTP数据 || -----------------------------------------------------------------> | 应用层 |
||==========|| +------------+
|| ||
|| ||
||==========||==========|| +------------+
|| HTTP数据 || TCP首部 || --------------------- TCP数据包 ---------------------> | 传输层 |
||======================|| +------------+
|| ||
|| <---TCP数据包---> ||
||======================||=========|| +------------+
|| HTTP数据 || TCP首部 || IP首部 || ------------- IP数据包 -------------------> | 网络层 |
||=================================|| +------------+
|| ||
|| <-------- IP数据报--------> ||
||============||=================================||============|| +------------+
|| 以太网首部 || HTTP数据 || TCP首部 || IP首部 || 以太网首部 || -------- 以太网帧 ----------> | 数据链路层 |
================================================================= +------------+
发送端每通过一层则增加一层首部。发送端最后通过物理介质发送出去。
接收端与发送相反,一层一层解封装。
物理连路中不能传输任意长度的数据包,所以有了MTU:
- 大于MTU,网络层分片,MTU越多,分包越多,网络吞吐能力越差;
- 小于MTU,分包越少,网络吞吐越好。
数据流走向:
- 应用程序通过系统调用, 跟socket进行数据交互;
- soucket下来就是传输层、网络层、网络接口层;
- 下面就是网卡驱动以及硬件网卡设备等;
- 其中系统调用一直到网卡驱动程序(包含)都属于内核。
以太网帧
格式: | –目的地址– | –原地址– | –协议– | ——– 数据 ——–| - 填充- | -校验和-|
- 以太网真最大1518bytes,最小64bytes。
- 巨型帧:超出了标准以太网帧的最大尺寸(1500字节)。
- 巨型帧:可以携带最多9000字节的有效负载。
linux接收数据包的流程
linux接收数据包的流程基本如下:网卡—-内存地址——中断表—–中断处理函数——软中断——网络协议栈。
- 网卡收到网络包,通过DMA技术将网络包写入指定内存地址—即ring buffer,通过中断告知操作系统网络包已经到达。
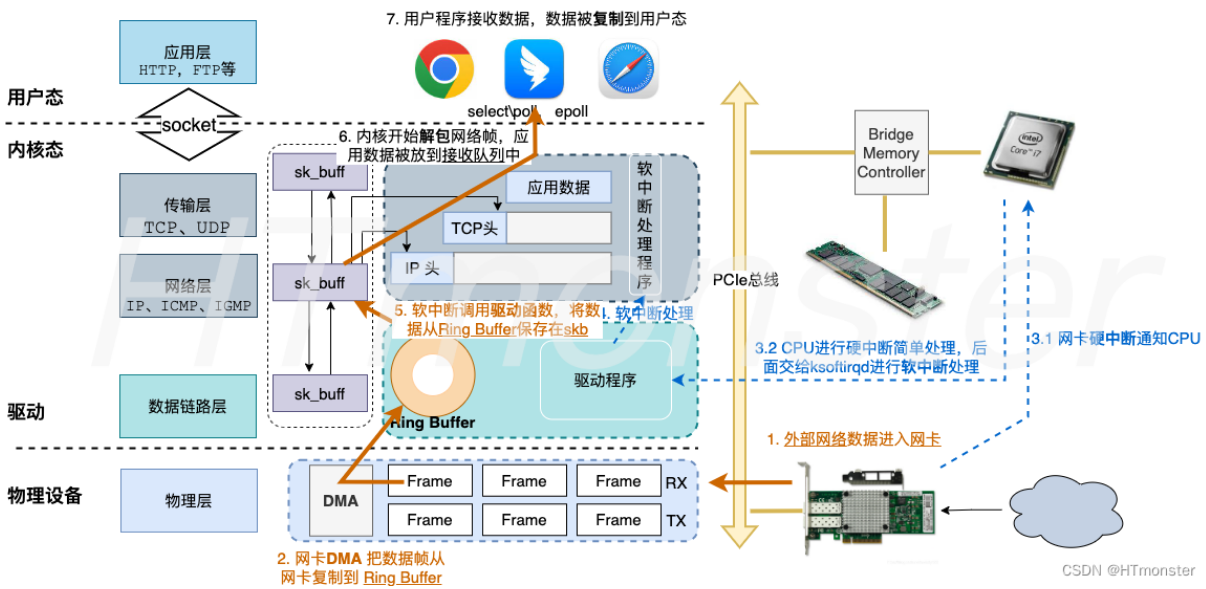 (该图来自:https://blog.csdn.net/weixin_38371073/article/details/125753454)
(该图来自:https://blog.csdn.net/weixin_38371073/article/details/125753454)
| 序号 | 网络层 | 控制流 | 数据流 |
|---|---|---|---|
| 1 | 物理层 | 外部网络→网卡 | |
| 2 | 物理层→数据链路层 | DMA复制数据 | 网卡Frame→Ring Buffer |
| 3.1 | 硬中断通知CPU | ||
| 3.2 | CPU交给ksoftirq软中断 | ||
| 4 | 数据链路层 | 软中断处理程序从驱动程序取数据 | |
| 5 | 数据链路层→(网络层+传输层) | Ring Buffer→sk_buff | |
| 6 | (网络层+传输层) | 按照协议栈解析报文 | →socket缓冲队列 |
| 7 | 应用层 | 内核sk_buff→用户态内存 |
硬中断
对于硬中断,处理流程是:硬中断—>CPU—->内核中的设备驱动程序 。 问题来了,来一个中断一次,cpu就开始处理数据包,当数据量非常多的时候,可能CPU没有时间去处理其他任务,所以在linux2.6引入了新的机制—-NAPI:中断+轮询, 流程如下:
- 网卡收到网络包,通过DMA技术将网络包写入指定内存地址—即ring buffer,
- 网卡向CPU发起硬件中断,CPU收到后根据中断表,调用注册的中断处理函数;
中断处理函数做的事情:
- 暂时屏蔽中断,表示内存中已经有数据了,告诉网卡下次收到数据直接写内存,不用通知cpu,表面不断被中断
- 然后发起软中断,恢复刚才屏蔽的中断。
软中断 +网络协议栈
软中断处理流程如下:
软中断—–》ksoftirqd线程—-》从ring buffer获取数据帧(表示为sk_buff),—->网络协议栈。
网络协议栈处理流程如下:
- 网络接口层检查合法性,去掉帧头帧尾, 给网络层;
- 网络层去除ip,判断给上层还是转发, 若给本机—去掉ip头给传输层;
- 去掉TCP/UDP头,根据四元组给对应socket,并把数据放到 Socket 的接收缓冲区。
- 应用层调用socket接口,将内核的 Socket 接收缓冲区的数据「拷贝」到应用层的缓冲区,然后唤醒用户进程。
所以,收包时至少有2次的内存拷贝:
- DMA拷贝:网卡收到数据时,DMA从接收缓冲区拷贝到系统内存,避免CPU的直接干预;
- 内核空间到应用空间的拷贝:从内核空间复制到用户空间,以便应用程序能够处理。
linux发包的流程
跟linux收包数据刚好相反: 应用程序调用socket—-到内核态的socket—-申请内核的sk_buffer—-数据拷贝到sk_buffer—-加入发送缓冲区—–网络协议栈从缓冲区取出sk_buffer—-然后协议栈从上到下处理—-sk_buff放到网卡的发送队列—–软中断告诉网卡驱动程序—-网卡读取sk_buffer到ringbufeer—映射到网卡内存的DMA区域—-发出—–硬中断释放内存
针对TCP传输,由于其有重传的机制,所以在发送数据时,拷贝一个新的 sk_buff 副本, 由于在网卡发送完成时,sk_buffer会释放掉,由于重传机制,所以在收到ack之前需要有一个sk_buffer,其实第一次发出去的数据时拷贝的sk_buffer,当收到ack后会清理原始的sk_bufeer。
sk_buffer可以表示各层的数据包,每层都要添加一个头部,是如何做到呢?是通过调整sk_buffer中的data指针(这个之后再分析)。通过同一个结构体在各个层级进行传递,而不是在每个层级传递时进行拷贝,极大地降低了CPU利用率。
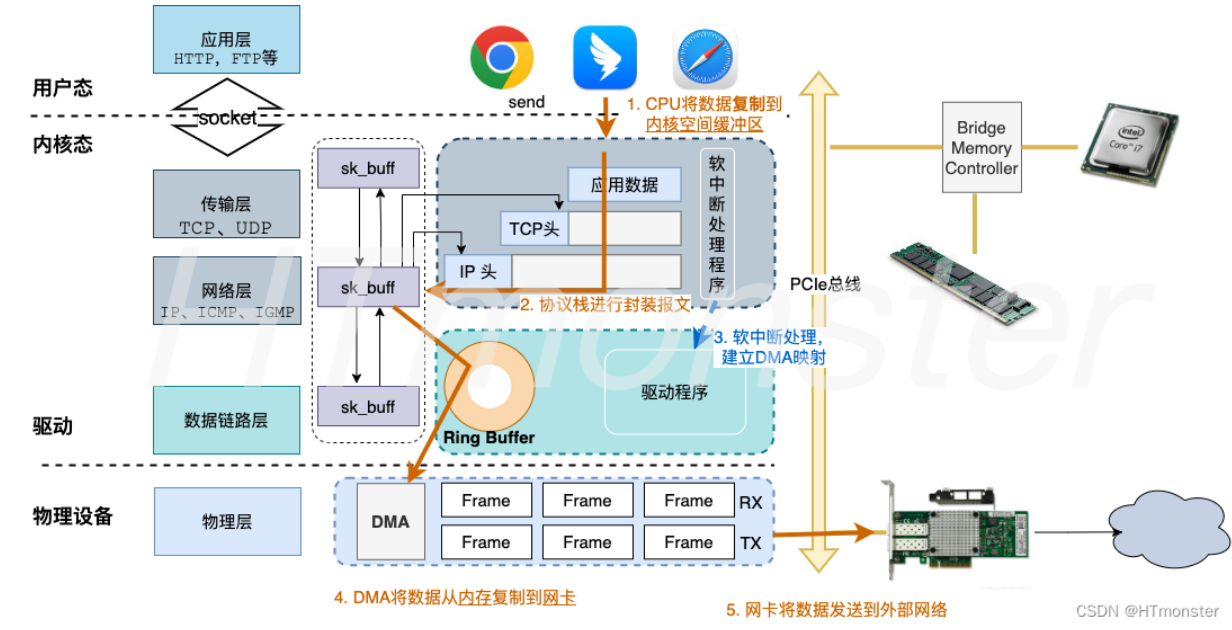 (该图来自:https://blog.csdn.net/weixin_38371073/article/details/125753454)
(该图来自:https://blog.csdn.net/weixin_38371073/article/details/125753454)
| 序号 | 网络层 | 控制流 | 数据流 |
|---|---|---|---|
| 1 | 应用层 | 用户态内存→内核态内存 | |
| 2 | 传输层+网络层 | 协议栈进行封装报文 | |
| 3 | 软中断建立DMA映射 | ||
| 4 | 传输层+网络层→数据链路层 | sk_buff→Ring Buffer | |
| 6 | 数据链路层→物理层 | Ring Buffer→网卡Frame | |
| 7 | 物理层 | 网卡→外部网络 |
所以,发包时总共有三次的内存拷贝:
- 系统调用时,将数据拷贝到内核的sk_bufeer,加入发送缓冲区;
- tcp传输时,拷贝一份,以便重传;
- 网络层发现sk_buff大于MTU时,申请额外的sk_buffer,将原来的sk_buffer分成多个小的。
sk_buffer结构体如下:
/* include/linux/skbuff.h */
struct sk_buff {
union {
struct {
/* These two members must be first.
这两个域是用来连接相关的skb的(如果有分片的话,可以通过它们将分片链接到一起),sk_buff是双链表结构。
*/
struct sk_buff *next; /*链表中的下一个skb*/
struct sk_buff *prev; /*链表中的上一个skb*/
union {
ktime_t tstamp; /*记录接受或者传输报文的时间戳*/
struct skb_mstamp skb_mstamp;
};
};
struct rb_node rbnode; /* 红黑树,used in netem, ip4 defrag, and tcp stack */
};
union {
struct sock *sk; /*指向报文所属的套接字指针*/
int ip_defrag_offset;
};
struct net_device *dev; /*记录接受或发送报文的网络设备*/
/*
* This is the control buffer. It is free to use for every
* layer. Please put your private variables there. If you
* want to keep them across layers you have to do a skb_clone()
* first. This is owned by whoever has the skb queued ATM.
*/
char cb[48] __aligned(8); /*保存与协议相关的控制信息,每个协议可能独立使用这些信息*/
unsigned long _skb_refdst; /*主要用于路由子系统,保存路由相关的东西*/
void (*destructor)(struct sk_buff *skb);
#ifdef CONFIG_XFRM
struct sec_path *sp;
#endif
#if defined(CONFIG_NF_CONNTRACK) || defined(CONFIG_NF_CONNTRACK_MODULE)
struct nf_conntrack *nfct;
#endif
#if IS_ENABLED(CONFIG_BRIDGE_NETFILTER)
struct nf_bridge_info *nf_bridge;
#endif
unsigned int len,
/*整个数据区域的长度,
这里的len = length(实际线性数据,不包括头空间和尾空间) + length(非线性数据)
len = (tail - data) + data_len
这个len中数据区长度是个有效长度,因为不删除协议头,
所以只计算有效协议头和包内容。如:当在L3时,不会计算L2的协议头长度。*/
data_len; /*非线性数据,length(实际线性数据 = skb->len - skb->data_len)*/
__u16 mac_len, /*mac层报头的长度*/
hdr_len; /*用于clone时,表示clone的skb的头长度*/
/* Following fields are _not_ copied in __copy_skb_header()
* Note that queue_mapping is here mostly to fill a hole.
*/
kmemcheck_bitfield_begin(flags1);
__u16 queue_mapping;
/* if you move cloned around you also must adapt those constants */
#ifdef __BIG_ENDIAN_BITFIELD
#define CLONED_MASK (1 << 7)
#else
#define CLONED_MASK 1
#endif
#define CLONED_OFFSET() offsetof(struct sk_buff, __cloned_offset)
__u8 __cloned_offset[0];
__u8 cloned:1,
nohdr:1,
fclone:2,
peeked:1,
head_frag:1,
xmit_more:1,
pfmemalloc:1;
kmemcheck_bitfield_end(flags1);
/* fields enclosed in headers_start/headers_end are copied
* using a single memcpy() in __copy_skb_header()
*/
/* private: */
__u32 headers_start[0];
/* public: */
/* if you move pkt_type around you also must adapt those constants */
#ifdef __BIG_ENDIAN_BITFIELD
#define PKT_TYPE_MAX (7 << 5)
#else
#define PKT_TYPE_MAX 7
#endif
#define PKT_TYPE_OFFSET() offsetof(struct sk_buff, __pkt_type_offset)
__u8 __pkt_type_offset[0];
__u8 pkt_type:3; /*标记帧的类型*/
__u8 ignore_df:1;
__u8 nfctinfo:3;
__u8 nf_trace:1;
__u8 ip_summed:2;
__u8 ooo_okay:1;
__u8 l4_hash:1;
__u8 sw_hash:1;
__u8 wifi_acked_valid:1;
__u8 wifi_acked:1;
__u8 no_fcs:1;
/* Indicates the inner headers are valid in the skbuff. */
__u8 encapsulation:1;
__u8 encap_hdr_csum:1;
__u8 csum_valid:1;
__u8 csum_complete_sw:1;
__u8 csum_level:2;
__u8 csum_bad:1;
#ifdef CONFIG_IPV6_NDISC_NODETYPE
__u8 ndisc_nodetype:2;
#endif
__u8 ipvs_property:1;
__u8 inner_protocol_type:1;
__u8 remcsum_offload:1;
#ifdef CONFIG_NET_SWITCHDEV
__u8 offload_fwd_mark:1;
#endif
/* 2, 4 or 5 bit hole */
#ifdef CONFIG_NET_SCHED
__u16 tc_index; /* traffic control index */
#ifdef CONFIG_NET_CLS_ACT
__u16 tc_verd; /* traffic control verdict */
#endif
#endif
union {
__wsum csum;
struct {
__u16 csum_start;
__u16 csum_offset;
};
};
__u32 priority; /*优先级,主要用于QOS*/
int skb_iif; /*接收设备的index*/
__u32 hash;
__be16 vlan_proto;
__u16 vlan_tci;
#if defined(CONFIG_NET_RX_BUSY_POLL) || defined(CONFIG_XPS)
union {
unsigned int napi_id;
unsigned int sender_cpu;
};
#endif
#ifdef CONFIG_NETWORK_SECMARK
__u32 secmark;
#endif
union {
__u32 mark;
__u32 reserved_tailroom;
};
union {
__be16 inner_protocol;
__u8 inner_ipproto;
};
__u16 inner_transport_header;
__u16 inner_network_header;
__u16 inner_mac_header;
__be16 protocol; /*协议类型*/
__u16 transport_header;
__u16 network_header;
__u16 mac_header;
/* private: */
__u32 headers_end[0];
/* public: */
/* These elements must be at the end, see alloc_skb() for details. */
sk_buff_data_t tail; /*指向数据区中实际数据结束的位置*/
sk_buff_data_t end; /*指向数据区中结束的位置(非实际数据区域结束位置)*/
unsigned char *head, /* 指向数据区中开始的位置(非实际数据区域开始位置)*/
*data; /*指向数据区中实际数据开始的位置*/
unsigned int truesize;
atomic_t users; /*缓冲区总长度*/
};